


Introducing SDF - The Semantic Data Fabric
Modern SQL Development for Enterprise Scale Big Data


Data development at enterprise scale is really hard. Data organizations need to rapidly deliver insights while managing a complex landscape of governance and privacy regulations.
Unfortunately, data engineering tools have not kept up with the rapid advancements seen in software engineering. The result is a patchwork of fragmented tools glued together to maintain an organization's data infrastructure. A mess of exporters, importers, and data connectors - crucial semantics are lost.
We’ve personally experienced this at Microsoft and Meta, and worked to tackle it as architects of Azure BigData products, Microsoft’s One Engineering effort, and Meta's Unified Programming Model (UPM) for data engineering.
We found that a deep semantic understanding of the whole warehouse is needed to solve this challenge at scale. Today we proudly announce the solution, SDF: The Semantic Data Fabric.

Who Are We?
Researchers turned engineers turned product junkies and developer tool aficionados.
Our team collectively has over 12,000 citations, four dozen patents, and hundreds of thousands of app-store downloads. We’ve had a key hand in building everything from Windows (quite literally the build system for Windows), the .Net task parallel library, Pytorch (specifically torch-arrow), Language Integrated Queries (LINQ) for .Net, core Azure, Microsoft Cosmos, and most notably Meta’s Data warehouse.
You can find us on Linkedin, or Twitter, or send us an email directly at info@sdf.com.
What is SDF?
At its core, SDF is a compiler and build system that leverages static analysis to comprehensively examine SQL code at warehouse scale. By considering all queries in any dialect simultaneously, SDF builds a rich dependency graph and provides a holistic view of your data assets, empowering you to uncover problems proactively and optimize your data infrastructure like never before.
The standout feature of SDF is its ability to annotate your SQL sources with rich metadata and reason about them together. SDF metadata can range from simple types and classifiers (PII) to table visibility and privacy policies (Anonymize). When SDF performs its static analysis, it takes this metadata into account, propagates it throughout your SQL sources with Information Flow Theory, and enforces built-in and user-defined rules. We call these Checks. Here are some simple examples of powerful SDF Checks:
Check Data Privacy: Ensure all personally identifiable information (PII) is appropriately anonymized
Check Data Ownership: Guarantee every table has an owner (a staple of GDPR)
Check Data Quality: Prevent different currency types from combining in calculations (e.g. preventing £ + $ )
The above mentioned capabilities make SDF a truly type and privacy aware development system for SQL. SDF catches potential logic & code errors earlier, during development; guaranteeing data quality and data privacy throughout an organization. This is in stark contrast to traditional methods that require expensive observation and manual inspection.
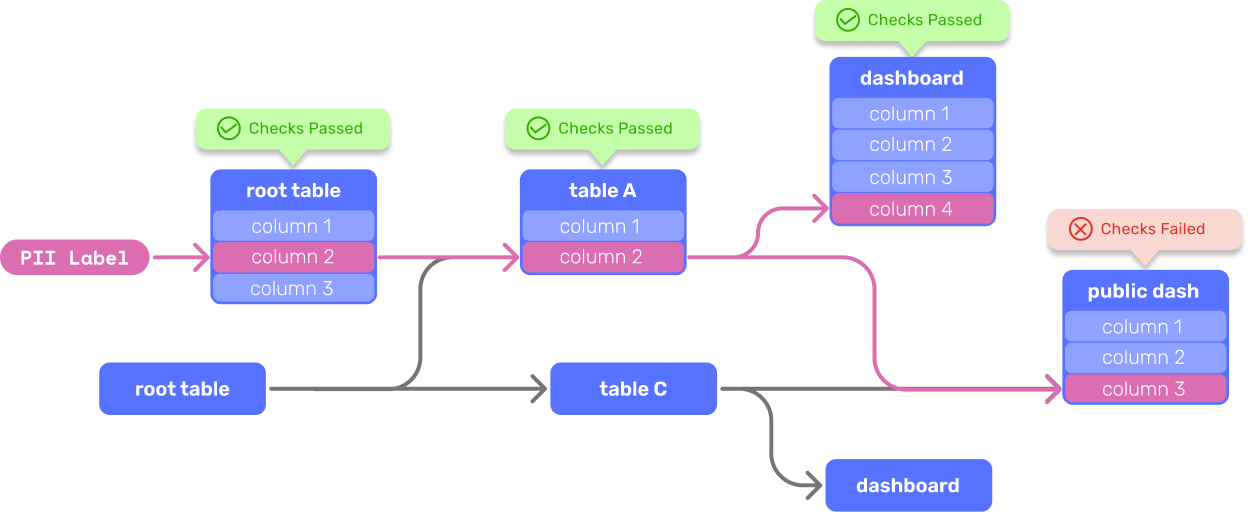
The result of SDF's warehouse analysis is an information schema rich in user authored and automatically inferred metadata. You can explore the information schema with SQL, use it to write your own Checks, integrate them into existing workflows and create powerful CI/CD safeguards for your organization.
Features
A Powerful Engine
The proprietary SDF engine includes a multi-dialect SQL compiler, static analyzer, dependency manager, and build cache - all wrapped in an easy to use CLI. It is written in highly efficient Rust (on top of Datafusion’s incredible core) allowing us to distribute it natively for multiple operating systems (Linux, Mac, and Windows) and microarchitectures (X86, ARM). Installation takes seconds and SDF supports automatic updates.

A Simple Authoring Framework
SDF represents your warehouse and metadata in versioned, verifiable code. Metadata and configurations are added to SDF with easy-to-use YAML files.
SDF Workspaces (workspace.sdf.yml) are similar to package.json (for Node.js) or Cargo.toml (for Rust). They’re used to organize and manage projects. But, unlike these other package systems which only specify configurations, SDF allows you to specify data asset definitions in YML as well. We call these definition blocks and they can be used to define or enrich tables, functions, classifiers, and more.
# --------------------- #
# An SDF Workspace #
# --------------------- #
workspace:
edition: "1.1"
name: "Example SDF Workspace"
dialect: presto
includes:
- path: sources/ # Folder with SQL Sources
code-checks:
- name: No_Currency_Mismatch
description: Never mix Currencies
assert: not-exists
path: checks/no_currency_mismatch.sql
---
classifier: # declaring a classifier
name: CURRENCY
labels:
- name: usd
- name: cad
---
table: # Attaching metadata to the lineitem table
name: lineitem
description: Contains sale & purchase details
columns:
- name: l_price
classifiers:
- CURRENCY.usdA Native Cloud Service
The SDF cloud offers an automatically curated data catalog, semantic search, and interactive data map of your data warehouse. Seamlessly search and visualize SQL artifacts, metadata, and classifier information flows backed by our compiled column level lineage.
SDF acts as your trusted partner in data governance and quality efforts, fostering collaboration and communication between all data stakeholders.
Benefits
Unprecedented Visibility: Gain a global view of your SQL ecosystem with static analysis at warehouse scale.
Enhanced Privacy & Security: Write compile-time code checks to safeguard sensitive data from unauthorized access.
Automated Metadata Capabilities: Annotate less than 1% of columns and let SDF automate the rest. Classifiers and policies automatically flow through all table dependencies for enhanced documentation and governance.
Proactive Error Prevention: Leverage compile time analysis and CI/CD integration to catch mistakes before they impact your data integrity.
Comprehensive Data Lineage Analysis: Understand the flow and transformation of your data to troubleshoot and comply with regulations effectively.
Ease of integration: Analyze your SQL as-is and integrate SDF’s analysis results into your development process.
Cloud Native: All SDF deployments exist in a secure environment.
What’s Next?
Great software ecosystems start with powerful compilers.
Today, SDF focuses on a deep understanding of your warehouse in order to build consistent representations of data, modernize and automate data quality and simplify governance. Tomorrow, these foundations will help SDF expand beyond static analysis to dynamic execution by optimizing compute and powering intelligent workflows. We plan on introducing more supported SQL dialects, AI authoring and classification, built in query execution, data checks and more. As a true Data Fabric engine, SDF will revolutionize the way we develop and manage our Big Data solutions.
SDF is ready for enterprise use now, and will be released publicly in the coming months.
Stay tuned, this is just the start.
It looks simple and performant. Are there any pre-built code checks or everything must be coded in separate SQL files?